



A Comprehensive Guide to Xilinx FPGA: Architecture, Advantages, and Key Applications
 406
406Global electronic component supplier AMPHEO PTY LTD: Rich inventory for one-stop shopping. Inquire easily, and receive fast, customized solutions and quotes.
1. Xilinx FPGA Introduction
Field Programmable Gate Arrays (FPGAs) from Xilinx are crucial components in various advanced digital applications. Known for their flexibility, scalability, and wide range of IP core support, Xilinx FPGAs empower engineers and designers to build high-performance, custom solutions. This guide delves into the architecture, benefits, and key applications of Xilinx FPGAs, offering practical insights to help hardware engineers, digital designers, and beginners make informed decisions.
2. Understanding Xilinx FPGA Architecture
Overview of FPGA Series
Xilinx's FPGA portfolio encompasses multiple series, each optimized for specific use cases:
Product Series Comparison
| Series | Performance | Power Efficiency | Cost Efficiency | Target Applications |
|---|---|---|---|---|
| Virtex | Highest | Moderate | Premium | HPC, AI/ML, 5G |
| Kintex | High | Good | Mid-Premium | Video, Medical |
| Artix | Moderate | Very Good | Economic | Industrial, SDR |
| Spartan | Basic | Excellent | Most Economic | Consumer, IoT |
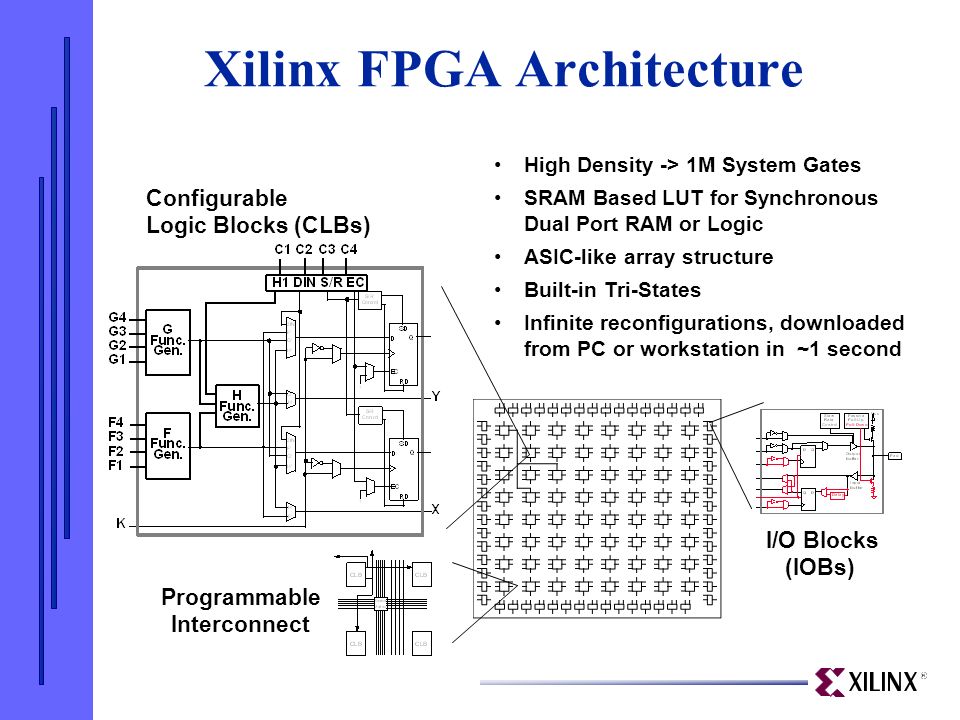
2.1 Configurable Logic Blocks (CLB)
Core Components
- Look-Up Tables (LUTs)
- 6-input LUT architecture
- Configurable as:
- Single 6-input LUT
- Dual 5-input LUTs
- Quad 4-input LUTs
- Support for:
- Logic functions
- ROM implementation
- Distributed RAM
- Shift registers
- Flip-Flops
- Dual flip-flop per LUT
- Features:
- Clock enable
- Set/Reset capabilities
- Initial state configuration
- Alternative D or latch modes
- Fast Carry Logic
- Dedicated carry chain
- Support for:
- High-speed arithmetic
- Comparators
- Counters
- Wide multiplexers
CLB Configuration Options
- Logic Mode
LUT → FF → Output- Traditional combinatorial logic
- Sequential logic elements
- Complex function implementation
- Memory Mode
LUT (as RAM) → Control Logic → Output- Distributed memory implementation
- High-speed local storage
- Custom memory configurations
2.2 Programmable Interconnects
Interconnect Types
- Switch Matrices
- Programmable routing nodes
- Connection types:
- Direct connections
- Double-length lines
- Long lines
- Global lines
- Routing Resources
- Local Interconnect
- Within CLB connections
- Adjacent CLB connections
- Minimal delay paths
- Regional Interconnect
- Medium-distance routing
- Clock region spanning
- Optimized for common paths
- Global Interconnect
- Chip-wide routing
- Clock distribution
- Reset signal distribution
- Local Interconnect
Timing Optimization
- Delay Management
- Path delay analysis
- Critical path optimization
- Timing constraint implementation
- Clock Domain Crossing
- Synchronization techniques
- Clock skew management
- Meta-stability handling
2.3 High-Performance DSP Modules
DSP48E2 Slice Architecture
- Core Components
- 27x18 multiplier
- 48-bit accumulator
- Pre-adder/subtractor
- Pattern detector
- Operational Modes
- Multiplication
- Multiply-accumulate
- Three-input addition
- Barrel shifting
- Wide-bus multiplexing
DSP Applications
- Signal Processing
- FIR filters
- FFT computation
- Digital down/up conversion
- Correlation/convolution
- Arithmetic Operations
- Fixed-point arithmetic
- Floating-point support
- Complex number processing
- CORDIC algorithms
Performance Metrics
- Speed Grade Variations
Speed Grade Max Frequency Power Consumption -1 300 MHz Lowest -2 500 MHz Moderate -3 700 MHz Highest - Resource Utilization
- Multiply-accumulate operations per clock
- Power efficiency metrics
- Resource sharing capabilities
Implementation Considerations
- Design Optimization
- Pipeline stages optimization
- Resource sharing strategies
- Clock frequency selection
- Power/performance tradeoffs
- Integration Guidelines
- Interface timing
- Data alignment
- Control signal management
- Clock domain considerations
This architectural understanding is crucial for:
- Optimal resource utilization
- Performance maximization
- Power consumption management
- Efficient design implementation
3. Key Advantages of Xilinx FPGA
3.1 Unmatched Flexibility
Design Adaptability
- Hardware Reconfiguration
- Runtime reconfiguration capabilities
- Partial reconfiguration support
- Multiple configuration modes:
- JTAG configuration
- Master/Slave Serial
- Master/Slave Parallel
- SPI/BPI Flash
- Design Iteration Benefits
- Development cost comparison:
Design Changes FPGA Cost ASIC Cost Initial $50K $500K+ Minor Revision $0 $100K+ Major Revision $0 $300K+
- Development cost comparison:
- Time-to-Market Advantages
- Rapid prototyping capability
- Quick design validation
- Immediate bug fixes
- Feature additions without hardware changes
Implementation Flexibility
- Resource Allocation
- Dynamic resource assignment
- Custom hardware architectures
- Optimized resource utilization
- Scalable designs
- Interface Adaptability
- Multiple I/O standards support
- Configurable voltage levels
- Protocol adaptation capability
- Custom interface development
3.2 Comprehensive IP Core Library
Available IP Categories
- Communication Protocols
- Ethernet (1G/10G/100G)
- PCIe Gen1-4
- JESD204B/C
- USB 2.0/3.0
- CAN/LIN/FlexRay
- Processing Systems
- Microprocessor cores
- DSP functions
- Memory controllers
- DMA engines
- Specialized Functions
Category Available IPs Integration Time Saving AI/ML 20+ 3-6 months Vision 15+ 2-4 months Security 10+ 4-8 months Audio 12+ 1-3 months
IP Integration Benefits
- Development Efficiency
- Reduced verification time
- Proven functionality
- Optimized performance
- Professional support
- Cost Savings
- Reduced development resources
- Lower verification costs
- Minimized risk
- Faster time-to-market
3.3 High Parallel Processing Capabilities
Parallel Architecture Advantages
- Processing Performance
- Concurrent operation execution
- Pipeline implementation
- Custom datapath creation
- Deterministic timing
- Performance Comparison
Application Type FPGA vs CPU FPGA vs GPU Image Processing 10-20x 2-5x Data Analytics 15-30x 3-8x Cryptography 20-50x 5-15x Signal Processing 25-40x 4-10x
Application-Specific Optimizations
- Deep Learning Inference
- Neural network acceleration
- Custom precision options
- Layer fusion optimization
- Batch processing support
- Video Processing
- Real-time processing
- Multiple stream handling
- Custom filter implementation
- Resolution scaling
- Network Processing
- Packet inspection
- Protocol conversion
- Traffic management
- Quality of Service (QoS)
Implementation Examples
- AI Acceleration

- Signal Processing
- Concurrent filter operation
- Parallel FFT computation
- Multiple channel processing
- Real-time analysis
Resource Utilization Optimization
- Design Considerations
- Resource sharing strategies
- Pipeline balancing
- Clock domain optimization
- Power efficiency
- Performance Metrics
- Throughput optimization
- Latency reduction
- Resource efficiency
- Power consumption
Industry-Specific Benefits
- Telecommunications
- 5G signal processing
- Network packet analysis
- Protocol adaptation
- Quality of Service
- Industrial Automation
- Real-time control
- Motion processing
- Safety systems
- Process monitoring
- Automotive
- ADAS processing
- Sensor fusion
- Network backbone
- Safety features
The combination of these advantages makes Xilinx FPGAs particularly valuable for:
- High-performance computing applications
- Real-time processing systems
- Adaptable hardware solutions
- Complex system integration
4.Applications of Xilinx FPGA
4.1 5G and Telecommunications
Implementation Areas
- Baseband Processing
- Signal processing performance metrics:
Function Latency Throughput FFT/IFFT < 1μs 20 Gsps FIR Filter < 2μs 15 Gsps MIMO < 5μs 10 Gsps
- Signal processing performance metrics:
- Digital Front-End Processing
- DUC/DDC implementations
- Crest factor reduction
- Digital predistortion
- Carrier aggregation
Real-World Performance Metrics
- Base Station Implementation
- 30% latency reduction
- 40% power efficiency improvement
- 25% resource utilization optimization
- Support for multiple standards:
- 5G NR
- LTE-Advanced
- OpenRAN compliance
- Network Infrastructure
- Packet processing capabilities
- Network slicing support
- Virtual network functions
- Quality of Service management
4.2 Autonomous Driving and ADAS
Core Functionalities
- Sensor Processing
- Camera data processing (4K @ 60fps)
- LiDAR point cloud processing
- Radar signal analysis
- Sensor fusion algorithms
- Real-time Performance
Function Latency Accuracy Object Detection < 50ms 95% Path Planning < 20ms 99% Lane Detection < 30ms 97% Collision Avoidance < 10ms 99.9%
System Integration
- Hardware Architecture

- Safety Features
- Functional safety compliance
- Redundancy implementation
- Error detection and correction
- System monitoring
4.3 Data Center Acceleration
AI Acceleration Performance
- Inference Metrics
Model Type CPU Baseline FPGA Speedup CNN 1x 20x RNN 1x 15x BERT 1x 18x ResNet-50 1x 22x - Resource Efficiency
- Power consumption reduction: 60%
- Rack space optimization: 40%
- Cooling requirements: 45% lower
- Total Cost of Ownership reduction: 35%
Workload Optimization
- Data Analytics
- Database acceleration
- Search optimization
- Real-time analytics
- Stream processing
- Network Functions
- Smart NICs
- Network virtualization
- Security functions
- Load balancing
5. Best Practices for FPGA Developers
5.1 Resource Optimization Strategies
Design Planning
- Resource Allocation
- LUT utilization guidelines
- DSP block placement
- Memory architecture planning
- I/O planning
- Timing Optimization

Tool Utilization
- Vivado Best Practices
- Project organization
- Version control integration
- Constraint management
- Report analysis
5.2 IP Core Integration
Selection Criteria
- Evaluation Metrics
Aspect Consideration Performance Required throughput and latency Resources Available LUTs, DSPs, Memory Integration Interface compatibility Support Documentation and updates - Integration Process
- Interface adaptation
- Clock domain handling
- Reset methodology
- Testing strategy
5.3 Scalability Planning
Architecture Considerations
- Future-Proofing
- Modular design approach
- Parameterized modules
- Interface standardization
- Documentation practices
- Upgrade Paths
- Resource headroom
- Performance margins
- Interface flexibility
- Power budget
Development Guidelines
- Code Organization
- Hierarchical structure
- Module independence
- Clear interfaces
- Version control
- Documentation Requirements
- Design specifications
- Interface definitions
- Test procedures
- Maintenance guides
5.4 Additional Best Practices
- Performance Optimization
- Pipeline optimization
- Clock domain management
- Critical path analysis
- Resource sharing
- Debug and Verification
- Simulation strategy
- Hardware debugging
- Performance monitoring
- System validation
- Power Management
- Dynamic power optimization
- Clock gating implementation
- Resource shutdown
- Thermal considerations
These best practices help ensure:
- Optimal design performance
- Reduced development time
- Improved maintainability
- Future scalability
- Reliable operation
Xilinx FPGAs hold a competitive edge over rivals such as Intel (formerly Altera) in several key areas. Xilinx’s Vivado Design Suite is recognized for offering a more intuitive user experience, particularly in resource management and timing analysis. Additionally, Xilinx provides a more extensive library of IP cores, covering advanced applications in communication, security, and AI.
Xilinx has also made significant strides in the field of AI acceleration and adaptive computing, with products like the Versal ACAP (Adaptive Compute Acceleration Platform), which combines FPGA flexibility with the performance of dedicated hardware. This innovative approach gives Xilinx a technological advantage in emerging applications, such as real-time AI inference, advanced data analytics, and 5G communications. This makes Xilinx FPGAs the preferred choice for developers looking for comprehensive, high-performance solutions.
- Signal Processing